ビオンテックとファイザーのSARS-CoV-2ワクチンのソースコードのリバースエンジニアリング
他言語版: English (original version) / عربى / ελληνικά / 中文 (Weixin video, Youtube video) / 粵文 / bahasa Indonesia / Català / český / Deutsch / Español / 2فارسی / فارسی / Français / עִברִית / Hrvatski / Italiano / Nederlands / 日本語(柞刈湯葉氏版) / नेपाली / Polskie / русский / Português / Română / Slovensky / Slovenščina / Türk / український / 翻訳用Markdown / 日本語版Markdown
この記事は bert hubert 氏による記事 Reverse Engineering the source code of the BioNTech/Pfizer SARS-CoV-2 Vaccine の日本語訳です。
ようこそ! この記事ではビオンテック(BioNTech)とファイザー(Pfizer)のSARS-CoV-2向けmRNAワクチン(メッセンジャーRNAワクチン)のソースコードを一文字づつ見ていきます。
この記事の読みやすさと正確さの確認のために時間を割いてもらった多くの人々に感謝します。 すべての誤りの責任は自分にありますが、もし誤りがあれば bert@hubertnet.nl もしくは @PowerDNS_Bert までご連絡いただければ幸いです
(この日本語訳については masahiro.sakai@gmail.com もしくは @masahiro_sakai まで)
まず、ワクチンのソースコードという表現には違和感を感じるかも知れません。 ワクチンは腕に注射する液体なのに、そのソースコードとはどういうことなのでしょうか?
これはとても良い質問で、まずはビオンテックとファイザーのワクチンのソースコードの一部を見ていきましょう。 (このワクチンはBNT162b2 もしくは Tozinameran もしくは コミナティ筋注(Comirnaty) としても知られています。)

BNT162b2 mRNAワクチンの最初の500文字。出典: World Health Organization
BNT162b2 mRNAワクチンの中核となるのは、このデジタルなコードです。 これは4284文字で、したがって一連のツイートに収まるほどの長さしかありません。 ワクチン製造過程の一番最初は、このコードをDNAプリンター(!)にアップロードし、このバイト列を実際のDNAの分子に変換することです。

Codex DNA 社のDNAプリンタ BioXp 3200
DNAプリンタの出力は少量のDNAで、その後に多くの生物的・化学的な処理を経ることでワクチンのアンプルに収まっているRNAになります(RNAについては後で詳しく説明します)。 30マイクログラムの用量には実際に30マイクログラムのRNAが含まれています。 さらに、このmRNAを我々の細胞の中に運ぶためには、脂質による巧妙なパッケージングが用いられています。
RNAは、揮発性の「作業メモリー」版のDNAです。 DNAは生物学におけるフラッシュメモリのようなもので、永続性と内部的な冗長性があり、またとても信頼性が高いのです。 しかし、計算機と同様、フラッシュメモリ上のコードを直接実行することはなく、その前により高速で融通が効き、代わりに壊れやすいようなシステムへとコードを複製します。
計算機の場合にはそれはRAMで、生物の場合にはそれはRNAです。 これは特筆すべき対応です。 フラッシュメモリと異なり、RAMは甲斐甲斐しく手入れをしない限り、急速に状態が劣化します。 ファイザーとビオンテックのmRNAワクチンを超低温冷凍庫の最深部に保管しなくてはならないのも同じ理由です。 RNAは儚い花なのです。
RNAの一文字は、およそ 0.53·10⁻²¹ グラムの重さで、したがって 30 マイクログラムのワクチン用量には、およそ 6·10¹⁶ 文字が含まれています。 バイト単位で表現すると約14ペタバイト(PB)ですが、これが同じ4284文字の13兆回の繰り返しであることは言っておくべきでしょう。 ワクチンの実際の情報量は1キロバイトちょっとしかありません。 ちなみに、SARS-CoV-2それ自体は約7.5キロバイトです。
更新: 元記事の数字には誤りがあったので、 正しい計算のスプレッドシートを用意しました。
背景を少しだけ
DNAはデジタルなコードです。 ただし、計算機が0と1を使っているのに対して、生命は A, C, G, UもしくはTの4つのコード(「ヌクレオチド」「ヌクレオシド」「塩基」などと呼ばれます)を用います。
計算機では0と1を電荷の有無、電流(量)、磁化、電圧、信号の変調、反射率の変化などによって保存します。 言い方を変えると、0と1は抽象的な概念ではなく、電子もしくは他の物理的実体として存在しているのです。
自然では、A, C, G, U/T は分子であり、DNA(もしくはRNA)の鎖として保存されています。
計算機では、8ビットを1バイトとしてグループ化し、バイトがデータ処理の典型的な単位となります。
自然では、3つのヌクレオチドを1コドンとしてグループ化し、コドンが処理の典型的な単位となります。 コドンは6ビットの情報を持ちます(DNAの文字あたり2ビットで3文字なので6ビット。つまり、2⁶ = 64 通りの異なるコドンの値があります)。
ここまでは非常にデジタルな話でした。 もし疑問に思ったことがあれば、デジタルコードが記載されたWHOのドキュメントを自分の目で見てみてください。
さらなる文献がここにあります。 このリンク ‘What is life’ (「生命とは何か」) は、このページの残りの意味を理解するのに役立つかも知れません。 もしくは、動画の方が良ければ、二時間の動画もあります。
ではこのコードは何をするのでしょうか?
ワクチンは、実際にその病気になることなく、ある病原菌との戦い方を我々の免疫系に教えるためのものです。 歴史的には、弱毒化もしくは不活化したウイルスと、免疫系を怖がらせて行動を起こさせるための「アジュバント」(adjuvant)を注射することによって行われてきました。 これは数十億個の卵や昆虫を用いて行われる極めてアナログな技術です。 さらに、多くの運とリードタイムが必要でした。 時には、異なる(無関係の)ウイルスが用いられることもありました。
mRNAワクチンは、「免疫系を教育する」という同じ目的を、レーザーのような方法で実現します。 ここでレーザーのようなと言っているのは、非常に狭められたという意味と、非常に強力という2つの意味でです。
ではどう機能するかを説明しましょう。 注射にはSARS-CoV-2の有名な「スパイク」タンパク質を表す一時的な遺伝物質が含まれています。 巧妙な化学的手段によって、ワクチンはこの遺伝物質を我々の細胞の一部の内部に取り入れます。
細胞に取り込まれた遺伝物質は、我々の免疫系が行動を起こすのに充分なSARS-CoV-2のスパイクタンパク質の生産を開始します。 スパイクタンパク質と、(より重要な)細胞が乗っ取られているという明確な兆候に直面して、我々の免疫系はスパイクタンパク質とその生成過程の「両方」の複数の側面に対抗する強力な対応手段を開発します。
これが有効性95%のワクチンを達成した仕組みなのです。
ソースコード!
ドレミの歌のように、最初から見ていきましょう。 WHOのドキュメントには便利な図があります:

これは一種の目次のようなものです。 小さな帽子のように描かれている「cap」(Cap構造)から見ていきましょう。
計算機上のファイルにいきなりオペコードを書いて実行することが出来ないのと同じように、生物学的オペレーティングシステムにはヘッダーが必要であり、リンカーや呼び出し規約のようなものも存在しています。
ワクチンのコードは以下の2つのヌクレオチドから始まります。
GA
これは DOS や Windows の実行ファイルが MZ から始まり、UNIXのスクリプトが #! から始まるのに対応しています。
生命の場合でもオペレーティングシステムの場合でも、これらの二文字はいかなる意味でも実行されることはありません。
しかし、それがないと何も起こらないため、そこに存在しなくてはならないのです。
mRNAのCap構造は多くの機能を持っています。 第一に細胞核から来たコードをマーキングします。 今回の場合、コードは細胞核から来たものではなく、ワクチン接種によってもたらされたものです。 しかし、細胞にそのことを伝える必要はありません。 Cap構造の存在は、ワクチンのコードを正当なものに見せかけ、コードが破壊されることを防ぎます。
また、最初の2つの GA ヌクレオチドは残りのRNAとは化学的に微妙に異なります。
その意味でこの GA はOOB(out-of-band)信号を伝達していると言えます。
5'(ファイブ・プライム)非翻訳領域
いくつか専門用語を使わせて下さい。 RNA分子は一方向にしか読み進むことが出来ません。 混乱しがちな名前ですが、読み始める位置は 5' (ファイブ・プライム) と呼ばれています。 そして、読み込みは 3' (スリー・プライム) 末端で終了します。
生命はタンパク質(やタンパク質によって作られる物質)によって構成されており、それらタンパク質はRNAによって記述されています。 RNAがタンパク質に変換される過程は翻訳と呼ばれます。
以下がワクチンの 5' 非翻訳領域(five prime untranslated region:5' UTR)で、従ってこれはタンパク質には翻訳されません:
GAAΨAAACΨAGΨAΨΨCΨΨCΨGGΨCCCCACAGACΨCAGAGAGAACCCGCCACC
ここで最初に驚くのは、通常のRNAは A, C, G, U (U は DNA では T として知られています) からなるのに対して、 ここには Ψ が含まれています。 これは一体どうしたことでしょうか?
これはこのワクチンの超絶巧妙な点です。 私達の肉体はウィルスに対抗する強力なシステム(“the original one”)を持っているため、細胞は外部から来たRNAを非常に嫌っていて、それが何かをする前に全力で破壊しようとします。
これは我々のワクチンにとってやや問題なので、免疫システムをこっそりやり過ごす必要があります。 何年にも渡る実験の結果、RNAにおけるUを微妙に変化させることで、免疫システムの目を逸らせることが分かっていました(マジで!)。
そこで、ビオンテックとファイザーのワクチンでは、すべての U を ψ で表される 1-メチル-3'-シュードウリジリル (1-methyl-3'-pseudouridylyl) に置き換えています。 非常に巧妙なのは、置き換えられた ψ は免疫系を鎮める一方で、細胞の関連する部分においては通常の U として受け入れられる点です。
計算機セキュリティーの分野にも同じトリックがあります。ファイアーウォールやセキュリティソフトウェアを混乱させる一方で、バックエンドのサーバーには受けいれられるように微妙に壊したメッセージを送信することで、サーバーをハックすることができることがあるのです。
これは過去に行った基礎科学研究の成果の収穫です。 Ψを用いるテクニックの発見者たちは、研究の資金を得て受け入れてもらうために闘わなくてはなりませんでした。 私達は皆このことに感謝すべきですし、いずれノーベル賞が彼らに授与されるであろうと私は確信しています。
ウイルスも ψ テクニックを使って我々の免疫システムを出し抜くことができるのかと、多くの人に聞かれました。 簡潔に答えると、その可能性は極めて低いです。 というのも、生命は 1-メチル-3'-シュードウリジリル ヌクレオチドを合成する機構を持っていないためです。 ウイルスは生命の機構に依存して自己複製を用いますが、必要な機構がそこには存在しないのです。 mRNAワクチンは人間の体内で急速に劣化するので、Ψに置き換えられたRNAがψが残った状態で複製される可能性はありません。 “No, Really, mRNA Vaccines Are Not Going To Affect Your DNA” (「mRNAワクチンはあなたのDNAには影響を与えません」)も参考になる記事です。
5' 非翻訳領域 に話を戻すと、この51文字は一体何をするのでしょうか? 自然に存在するものは何でもそうであるように、単一の明確な機能を持っているものはほとんど何もありません。
私達の細胞がRNAをタンパク質に翻訳する必要があるとき、リボソーム(ribosome)という機械を用いて行います。 リボソームはタンパク質の3Dプリンターのようなものです。 リボソームはRNA鎖を取り込み、それに基づいてアミノ酸の鎖を作り出し、タンパク質へと折り畳みます。
出典: [Wikipedia利用者Bensaccount](https://commons.wikimedia.org/wiki/File:Protein_translation.gif)
上図で起こっているのがこの過程です。 下部にある黒いリボン状のものがRNAであり、緑の部分に現れてくるリボン状のものが形成されるタンパク質です。 飛んできて飛び去っていくのが、アミノ酸およびRNAにフィットさせるためのアダプターです。
リボソームはRNA鎖の上に物理的に接していないと機能することが出来ません。 一旦RNAに接すると、さらに取り込むRNAに基づいてタンパク質の形成を始めます。 このことから、最初に接触した部分については読み込むことができないと想像することが出来ます。 このリボソームの着地領域としての機能は、非翻訳領域の機能のうちの一つです。 非翻訳領域は「導線」(lead-in)を提供するのです。
これに加えて、非翻訳領域は「いつ翻訳が起こるべきか」「どの程度翻訳が起こるべきか」というメタデータも含んでいます。 今回のワクチンでは、見つけられた限りで最も「今すぐ」を表す非翻訳領域が用いられており、これはαグロビン遺伝子(alpha globin gene)に由来するものです。 この遺伝子は多くの蛋白質を確実に生成することで知られています。 (WHOの資料によれば)過去数年で科学者たちはこの非翻訳領域を更に最適化する方法を見つけており、したがってこれはαグロビンの非翻訳領域そのものではなく、より改良されたものです。
S糖タンパク質シグナルペプチド
先に述べたように、ワクチンのゴールは細胞にSARS-CoV-2のスパイクタンパク質を大量に作らせることです。 これまでに、ワクチンのソースコード中の主にメタデータや「呼び出し規約」に関わる部分を見てきましたが、今度はウイルス性のタンパク質の領域を見ていきましょう。
ですが、見るべきメタデータの層がまだ一層残っています。 リボソームが(上の素晴らしいアニメーションのように)タンパク質を作ったあと、そのタンパク質はどこかに運ばれる必要があります。 この情報は「S糖タンパク質シグナルペプチド(拡張リーダー配列)」(S glycoprotein signal peptide (extended leader sequence))に符号化されています。
これを理解するためには、まず、タンパク質の先頭に(タンパク質自体の一部として符号化された)宛名ラベルの一種があります。 今回のケースでは、シグナルペプチドには「このタンパク質は『小胞体』(endoplasmic reticulum)経由細胞外放出行き」と書かれています。 スタートレックでさえ、これほど風変わりな用語はありません!
この「シグナルペプチド」は長いものではありませんが、実際に見てみるとウイルスのRNAとワクチンのRNAで違いがあることが分かります:
(ただし、比較を簡単にするために、風変わりなψを、通常のRNAのUに置き換えてあります)
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
ウイルス: AUG UUU GUU UUU CUU GUU UUA UUG CCA CUA GUC UCU AGU CAG UGU GUU
ワクチン: AUG UUC GUG UUC CUG GUG CUG CUG CCU CUG GUG UCC AGC CAG UGU GUG
! ! ! ! ! ! ! ! ! ! ! ! ! !
さあ、どうなっているでしょうか? RNAを3文字毎にグループして並べたのは偶然ではありません。 RNA 3文字はコドンを構成し、すべてのコドンは固有のアミノ酸を符号化しています。 そして、ワクチン中のシグナルペプチドはウイルス中のアミノ酸と完全に同じアミノ酸からなっています。
それならば、なぜRNAが異なるのでしょうか?
RNAには4種類の文字があり、コドンは3つの文字からなるので、4³=64種類のコドンが存在します。 しかし、アミノ酸はたったの20種類しかありません。 つまり、複数のコドンが同じアミノ酸を符号化しているのです。
生命は、RNAコドンをアミノ酸へ写像するために、以下のようなほぼ普遍的な表を用いています:
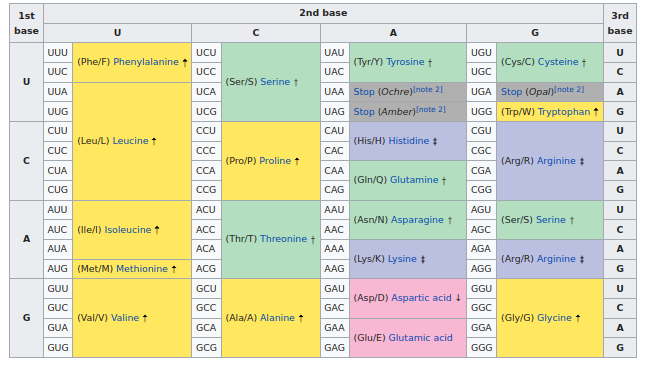
RNA・コドン表 (Wikipedia)
この表から、ワクチンでの変更(UUU → UUC)はすべて同義のコドンへの変更であることを見て取ることができます。 ワクチンのRNAコードは異なるものではあるものの、結果として得られるアミノ酸とタンパク質は同じものなのです。
さらに、注意深く見ることで、変更の多くはコドンの3文字目(上の比較で「3」と書かれている箇所で)で起こっていることが分かります。 そして、普遍コドン表を確認すると、実際3文字目の変更は生成されるアミノ酸を変えないことが多いことが分かります。
意味を変えない変更ならば、何故そもそも変更する必要があるのでしょうか? よく見てみると、一箇所を除いてすべての変更はCとGを増やす変更になっていることが分かります。
なぜそうするのでしょうか? 上でも述べたように、我々の免疫系は細胞外からやってきた「外来の」RNAを快く思っておらず、このワクチンでは免疫系による検知をすり抜けるために既にRNA中のUをψに置き換えたのでした。
しかし、GとCを多量に含むRNAも、より効率的にタンパク質に変換されることが分かっています。
そして、これはワクチンのRNAにおいて可能な限り多くの文字をGとCに置き換えることによって達成できるのです。
自分はCもしくはGの増加に繋がらないただ1箇所の変更である CCA から CCU への変更が少し気になっています。 もし、理由を知っている人がいたら、ぜひ教えて下さい! なお、一部のコドンは他のコドンよりも人間のゲノムの中でより頻繁に現れることは知っていますが、それが翻訳速度に大きな影響を与えないということも読みました。
実際のスパイクタンパク質
ワクチンRNAの続く3777文字も、同様にCとGを増やす「コドン最適化」が行われています。 スペースの都合でコード全体をここに掲載することはしませんが、非常に特殊な部分があるのでそこをクローズアップしてみましょう。 これはワクチンが機能するために必要で、したがって我々が普通の生活に戻る助けとなる部分です。
* *
L D K V E A E V Q I D R L I T G
ウイルス: CUU GAC AAA GUU GAG GCU GAA GUG CAA AUU GAU AGG UUG AUC ACA GGC
ワクチン: CUG GAC CCU CCU GAG GCC GAG GUG CAG AUC GAC AGA CUG AUC ACA GGC
L D P P E A E V Q I D R L I T G
! !!! !! ! ! ! ! ! ! !
ここでも意味を変えないようなRNAの変更がされていることが見て取れます。 例えば、最初のコドンはCUUからCUGに変更されています。 このようにワクチンにGを追加することで、タンパク質の生成を高めることができるのでした。 CUUとCUGは両方ともLで表されるロイシン (leucine) というアミノ酸を符号化しているので、生成されるタンパク質は変わりません。
ワクチン中のスパイクタンパク質の全体をウイルスのそれと比較すると、変更は二箇所を除いてはすべて意味を変えない変更です。 その二箇所がまさに今見ている箇所です。
上記の3つ目と4つ目のコドンが実際の変更箇所です。 KとVで表されるアミノ酸が両方ともプロリン (Proline) を表すPに置き換えられています。 そのために、Kに対しては3文字の変更(「!!!」)と、Vに対しては2文字のみの変更(「!!」)が必要です。
この二箇所の変更はワクチンの有効性を非常に高めることが判明しています。
一体何が起こっているのでしょうか? SARS-CoV-2の実際の粒子を見ると、たくさんのトゲ状になっているスパイクタンパク質が見えます:
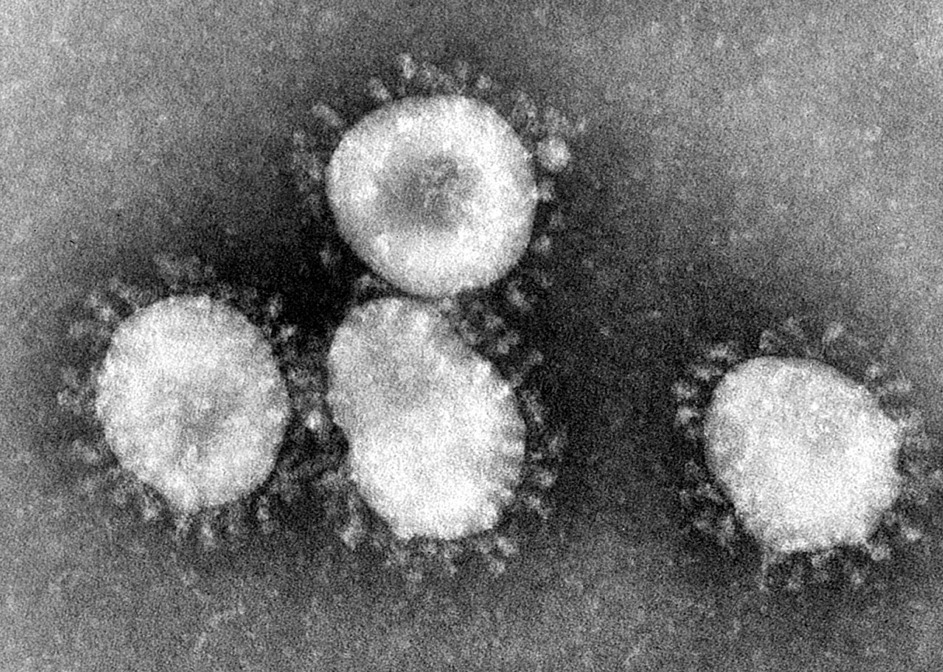
SARSウイルスの粒子 (Wikipedia)
これらのスパイクはウイルス本体(「ヌクレオカプシドタンパク質」)に固定されています。 ここで鍵となるのは、我々のワクチンはスパイクそれ自体を生成するのみで、スパイクをいかなる種類のウイルス本体にも固定しない点です。
固定されていない独立したスパイクタンパク質は、異なる構造に潰れてしまうことが判明しています。 それをワクチンとして接種すると、免疫を得ることが出来ますが、得られる免疫は潰れたスパイクタンパク質に対するものだけになってしまいます。
そして、実際のSARS-CoV-2はトゲトゲしたスパイクなので、ワクチンはあまり有効に機能しません。
ではどうすれば良いのでしょうか? 2017年に、適切な箇所を2つのプロリンで置き換えることによって、SARS-CoV-1 と MERS のSタンパク質を、ウイルス全体の一部にすることなく「結合前」(pre-fusion)の状態に保つことができることが報告されています。 なぜそんなことが出来るかというと、プロリンは剛性の高いアミノ酸であるためです。 プロリンは添え木のような役割を果たして、タンパク質を免疫系に見せたい状態のまま安定化させるのです。
これを発見した人達はきっと、耐えきれない気持ちの高まりから、ひっきりなしにハイタッチしながら歩き回っているに違いありません。 それに値するだけの価値があるのです。
追記! プロリンに関する発見に関わった マクレラン研究室(McLellan lab)から連絡がありました。 パンデミックが進行中なのでハイタッチは控えているものの、このワクチンに対して貢献できて光栄ですとのことでした。 また、彼ら以外の多くのグループや、労働者やボランティアの果たした役割の重要性についても強調していました。
タンパク質部分の終わりと、次のステップ
ソースコードの残りをスクロールしていくと、スパイクタンパク質の終わりに小さな変更が見つかります:
V L K G V K L H Y T s
ウイルス: GUG CUC AAA GGA GUC AAA UUA CAU UAC ACA UAA
ワクチン: GUG CUG AAG GGC GUG AAA CUG CAC UAC ACA UGA UGA
V L K G V K L H Y T s s
! ! ! ! ! ! ! !
タンパク質の終わりに、小文字のsで表される「終止」(stop)コドンがあります。 これはタンパク質の終了を表す行儀の良い方法です。 もとのウイルスではUAA終止コドン一つが用いられているのに対して、ワクチンの方では2つのUGA終止コドンが用いられています。 これはただのオマケかも知れません。
3'(スリー・プライム)非翻訳領域
リボソームが5’末端で「導線」(lead-in)として5’非翻訳領域を必要としていたように、タンパク質のコーディング領域の終わりには3'(スリー・プライム)非翻訳領域 と呼ばれる同様の機構があります。
3’非翻訳領域については、長々と説明することも出来ますが、ここではその代わりに英語版Wikipediaの説明を引用しておきましょう: 3’非翻訳領域は、mRNAの「局所化」「安定化」「核外輸送」「翻訳効率」に影響を与えることにより、遺伝子発現において重要な役割を果たします。 …… 3’非翻訳領域については現在ある程度分かってはいるものの、比較的謎の部分も多い。 (訳注:日本語版Wikipedia)
分かっていることは、ある種の3’非翻訳領域はタンパク質の発現の促進に非常に成功していることです。 WHOのドキュメントによれば、ビオンテックとファイザーのワクチンの3’非翻訳領域は、「RNAの安定性と高いタンパク質発現量を実現するために、AES(amino-terminal enhancer of split) mRNA とミトコンドリアの12SリボソームRNA(the mitochondrial encoded 12S ribosomal RNA)から取った」とのこと。 私に言えることは、「よくやった」ということです。
すべての終わりAAAAAAAAAAAAAAAAAAAAAA
mRNAの一番最後はポリアデニル化されています。 ポリアデニル化というのは大量のAAAAAAAAAAAAAAAAAAAの並びで終わっているということの気取った表現です。 mRNAですら2020年にはもう飽き飽きしてきているようです。
mRNAは何度も再利用することができますが、そのたびに末尾のAのうちのいくらかを失います。 Aを使い果たすと、そのmRNAは機能しなくなり破棄されます。 したがって、多量のAを持つ末尾は、劣化して破棄されることを防いでいます。
mRNAワクチンにとっての最適な末尾のAの数を見つけるための研究がされており、120かそこらがピークになっているという公開の文献を読んだとことがあります。
BNT162b2ワクチンの末尾は以下のようになっています:
****** ****
UAGCAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAGCAUAU GACUAAAAAA AAAAAAAAAA
AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAA
30個のAに続いて、「10文字のヌクレオチドのリンカー」(GCAUAUGACU) があり、更に70個のAが続いています。
リンカーがここに配置されていることに関しては様々な説があります。 何人かの人は、DNAプラスミドの安定性に関係していると教えてくれましたし、実際の専門家からも以下のメッセージをもらいました:
「ポリアデニル化された末尾中の10文字のヌクレオチドのリンカーは、mRNAへ転写するための鋳型になる合成DNA断片をつなぎ合わせるのに役立つのです。 また、T7 RNAポリメラーゼが紛れ込むことを減らし、転写されたmRNAの長さがより一様になるようにもします。」
まとめ
これで、BNT162b2ワクチンのmRNAの内容をすべて知ったことになり、そのほとんどの部分についてはそれが何故そこにあるのかが分かりました:
- RNAが通常のmRNAに見えるようにするためにあるCap構造、
- 既知の成功した5’非翻訳領域に基づいてさらに最適化された5’非翻訳領域、
- スパイクタンパク質を正しい場所に運ぶための、(元のウイルスのアミノ酸を100%コピーして)コドン最適化を行ったシグナルペプチド、
- もとのスパイクをコドン最適化し、タンパク質が正しい形になることを保証するために2つのプロリン置換を行ったスパイクタンパク質、
- 既知の成功した3’非翻訳領域に基づいて更に最適化された3’非翻訳領域、
- 「リンカー」を含む若干ミステリアスな多数のAによる末尾。
コドン最適化はmRNAのGとCを大量に増やします。 一方、Uの代わりにψ(1-メチル-3'-シュードウリジリル)を用いることで、免疫系を回避してワクチンのmRNAを十分長く存在させ、免疫系を訓練することを(実際には)助けることができます。
さらなる読み物など
2020年に私が行ったDNAに関する2時間の講演をここで見ることができます。 これはこのページと同様に計算機系の人々に向けた講演になっています。
それに加えて、私は「プログラマのためのDNA」(DNA for programmers)というページを2001年からメンテナンスしています。
我々の驚異の免疫系に関するこの紹介も楽しめるかも知れません。
最後に、私のブログの記事一覧には、DNA、SARS-CoV-2、COVIDに関する記事がかなりあります。